TK80/BSの
シンセシステムを復活/拡張したい~
その27
デジタルラダーフィルタの実験
2018年
9月3日
この週は遅い夏休みです。ガレージにアマゾンで購入したレベル変換基板が来ていました。早速、下ボードに実装しました。


アパートではアナログディスカバリから供給していたSPI-DACの外部リファレンスの2.5Vを3.3V電源から供給するように修正しました。グレードAのデバイスは電源と同じ電圧を外部リファレンスに入力できます。500オームの抵抗を直列にして3.3Vと接続しました。8ch~1chまで、0x8000~0x1000のダミーデータ(直流)を出力しているので、DACボードの1chのLED1と2chのLED2が消灯し、動作良好です。


下ボードにMC80+バスを配線しました。TK80/MSP430からの5V系データの8ビット、アドレスの4ビットをレベル変換ボードを介してFPAGに接続します。

FPGAの論理を変更して、SPI-DACの入力を直流のダミーデータから、DDSに変更します。全LEDが中輝度で高速点滅しています。アナログディスカバリで出力を確認しました。動作良好です。

9月4日
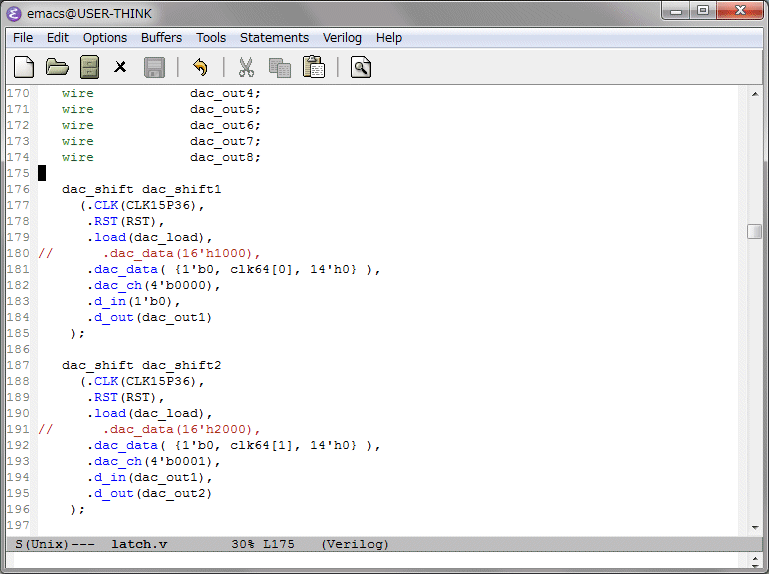
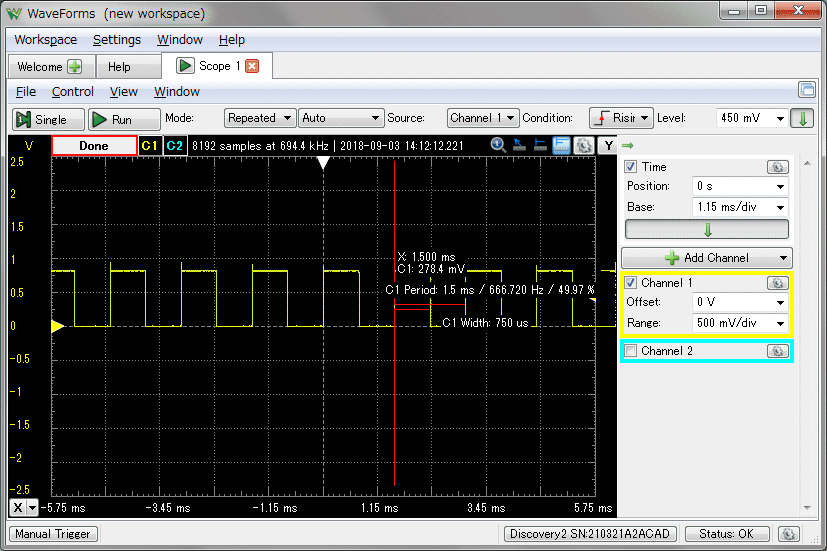
左はSPI-DACの入力をDDSに修正したシフトレジスタ部のソースコードです。DDSの出力は基本周波数の矩形波なので、16ビットあるDACの入力の15ビット目に接続しました。リファレンスが3.3Vなので、DACの出力は約0.825Vの矩形波になります。右はアナログディスカバリで確認したDACの出力波形です。DDS出力とサンプリングの48KHzは非同期なので48KHzの幅でジッタが発生します。矩形波なので目立ちますが、これは普通にアナログ信号を48KHzでサンプリングしているのと同じなので問題ありません。
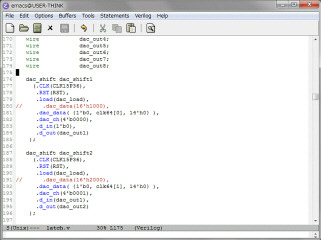
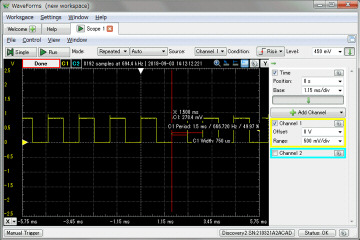
MC80+バスに接続して音出してみました。DCOの代わりに4ch分のみシンセに接続します。バスのラッチ、DDS部は実績がある回路なので、そのまま動作しました。MP3ファイルはこれです。

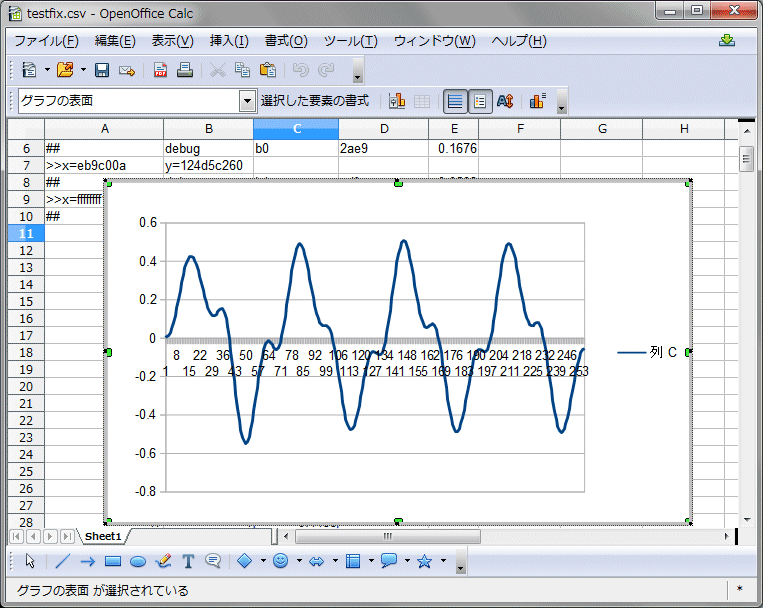
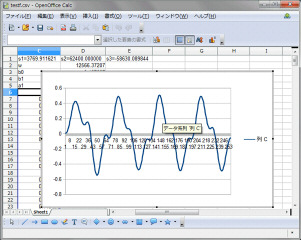
以前にPCで普通に作成した浮動小数点版のラダーフィルタのプログラム(大元はこれ)を固定小数点に変更して動作確認します。固定小数点をlong(64ビット)に割付て小数点部を下位の16ビットに設定しました。左が浮動小数点、右が固定小数点版です。カットオフ10KHz、フィードバック2.0です。
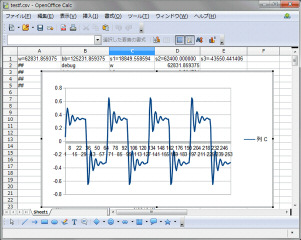
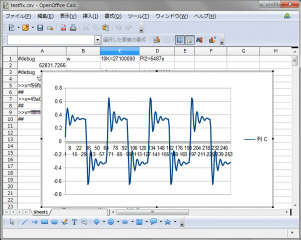
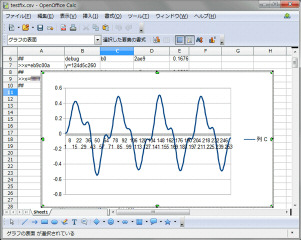
同じく、左が浮動小数点版、右が固定小数点版です。カットオフ2KHz、フィードバック3.0です。浮動小数点版も固定小数点版もほぼ同じ波形出力で問題なさそうです。
9月5日
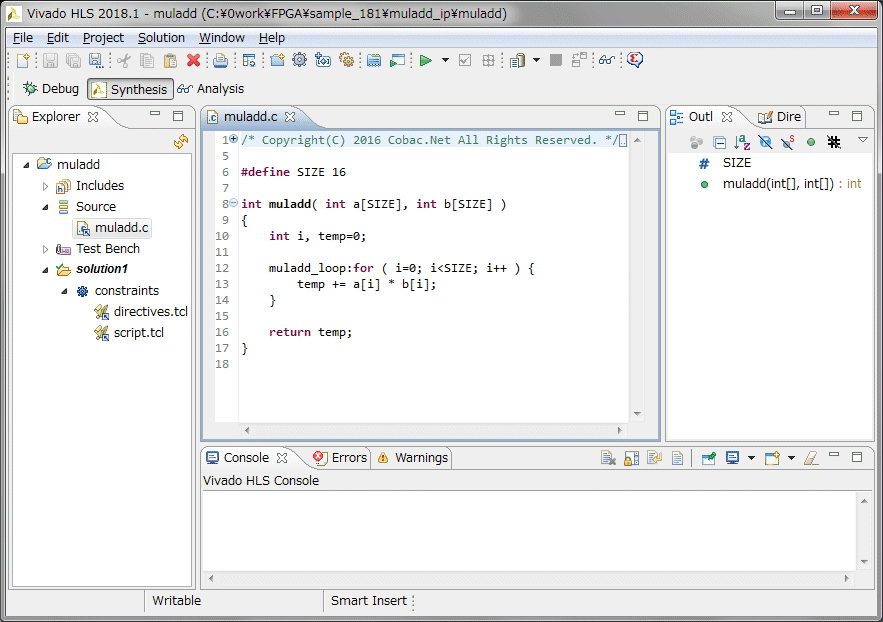
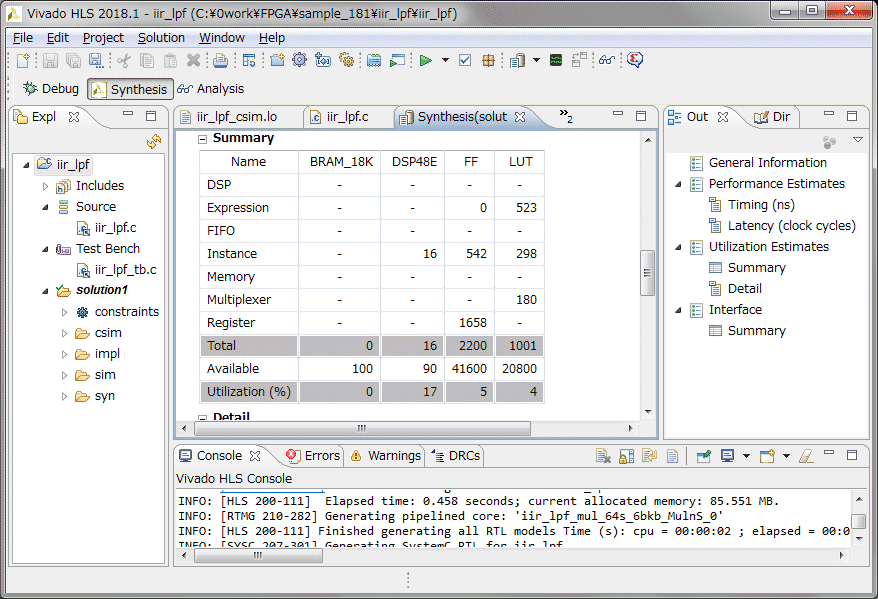
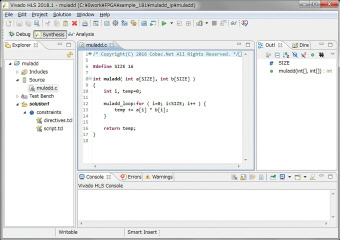
ラダーフィルタをVivadoのHLSで実装できるか確認します。まずは、HLSの勉強をします。FPGA大全の10章を見ながら一通りやってみました。左は配列同士を16回掛け算して終了する、簡単なサンプルコードです。右は合成すると動作速度とロジック使用量のレポートが得られます。全体のフローは分かりましたが、どうやって48KHzサンプリングに合わせればいいのかなどタイミング制御方法はまだ不明です。
9月6日
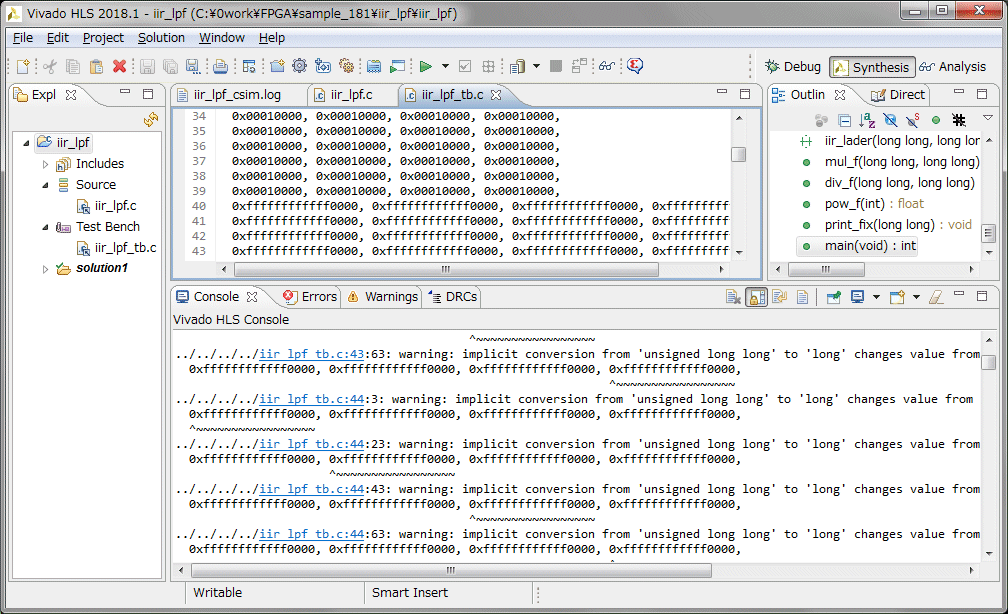
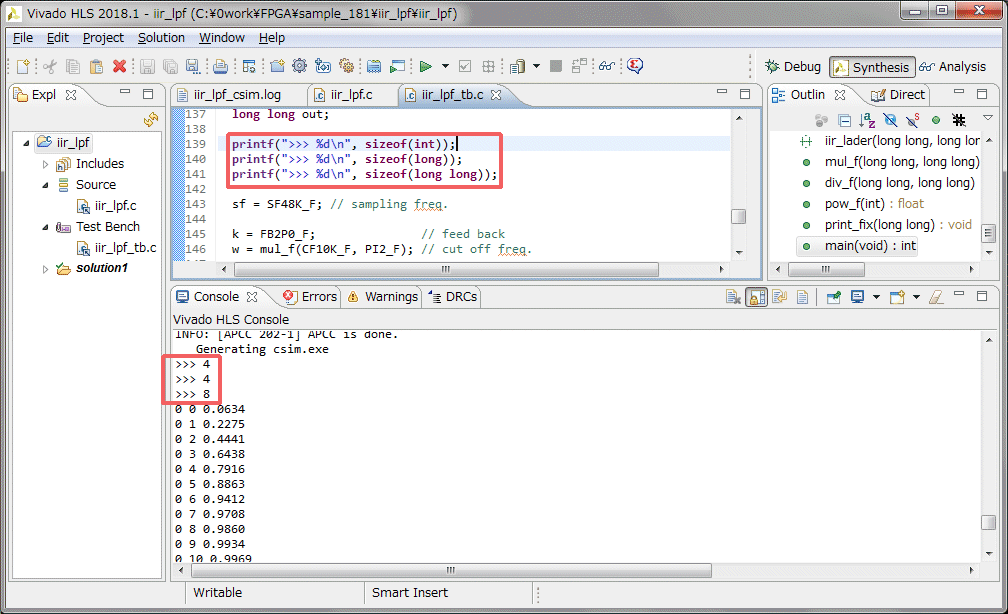
固定小数点版のラダーフィルタをテストベンチとフィルタ本体に分割し、HLSのプロジェクトとして作成します。コンパイル時にテストベンチの入力のダミーデータをlongで定義している所のサイズが合っていないというワーニングが出ます。
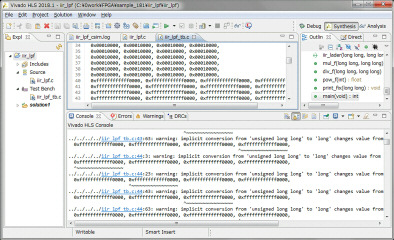
HLSのint、long、long longのサイズを確認していみます。4、4、8バイトです。
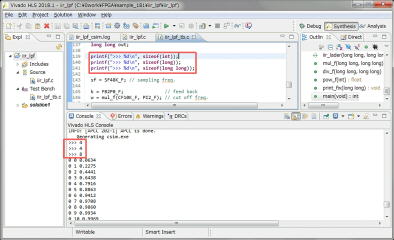
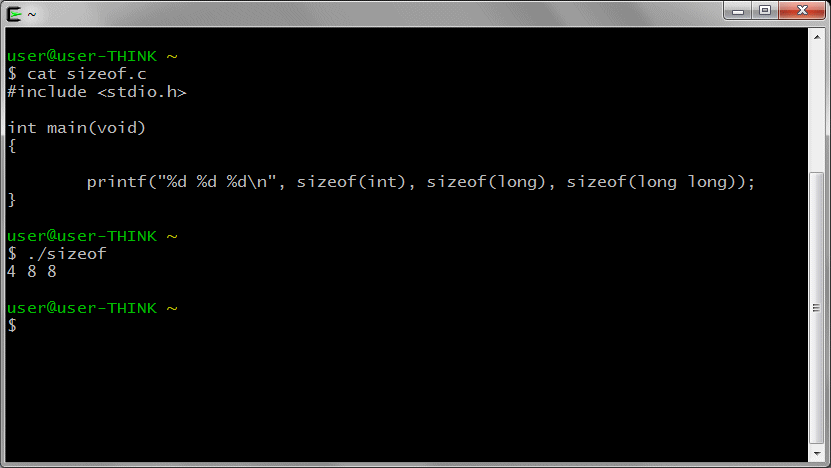
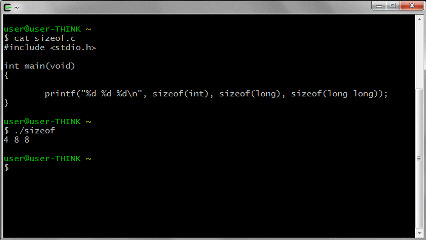
PCのcygwinのgccのint、long、long longのサイズを確認していみます。4、8、8バイトです。gccのlongは8バイトですが、HLSのlongは4バイトでした。上記のワーニングの原因が分かりました。
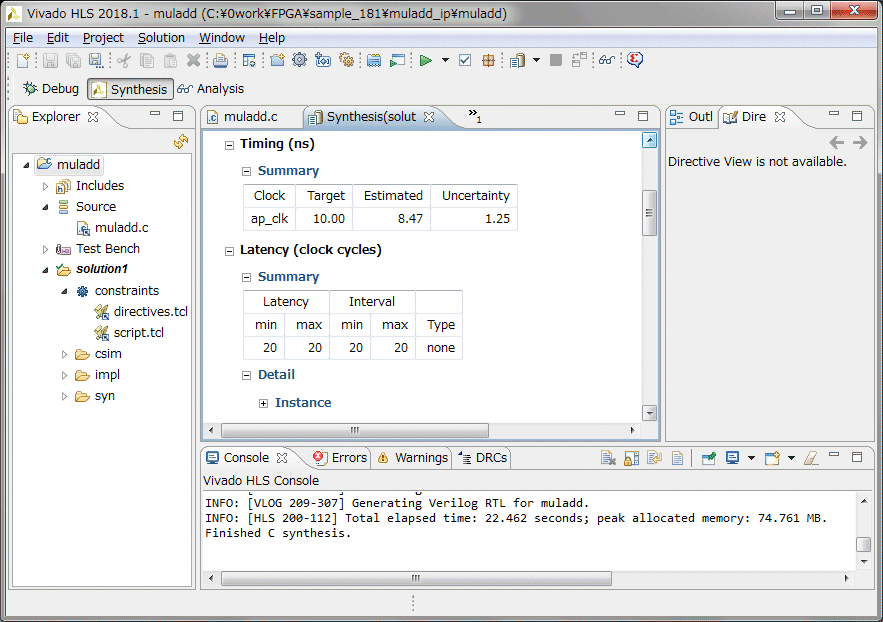
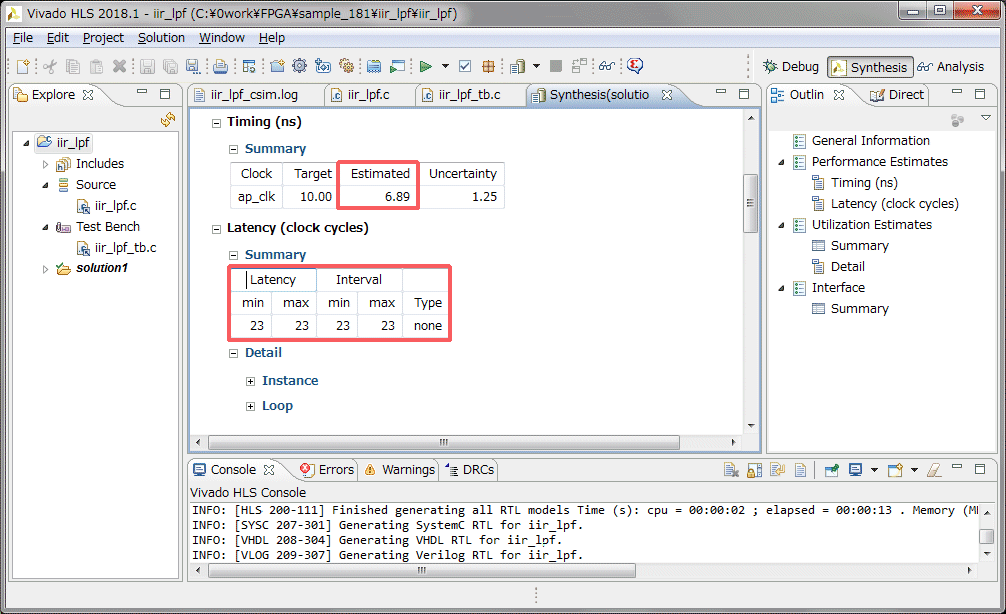
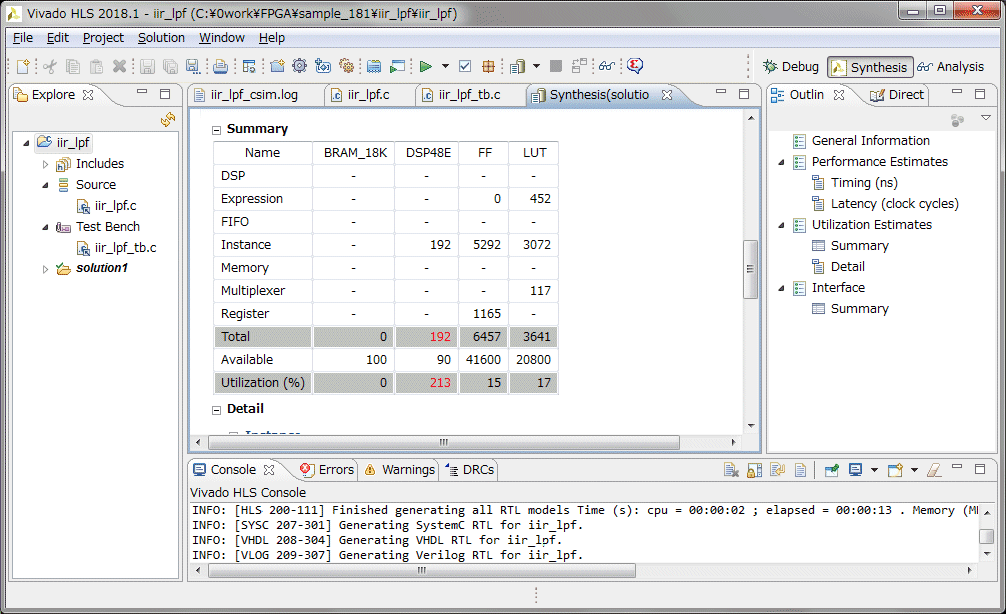
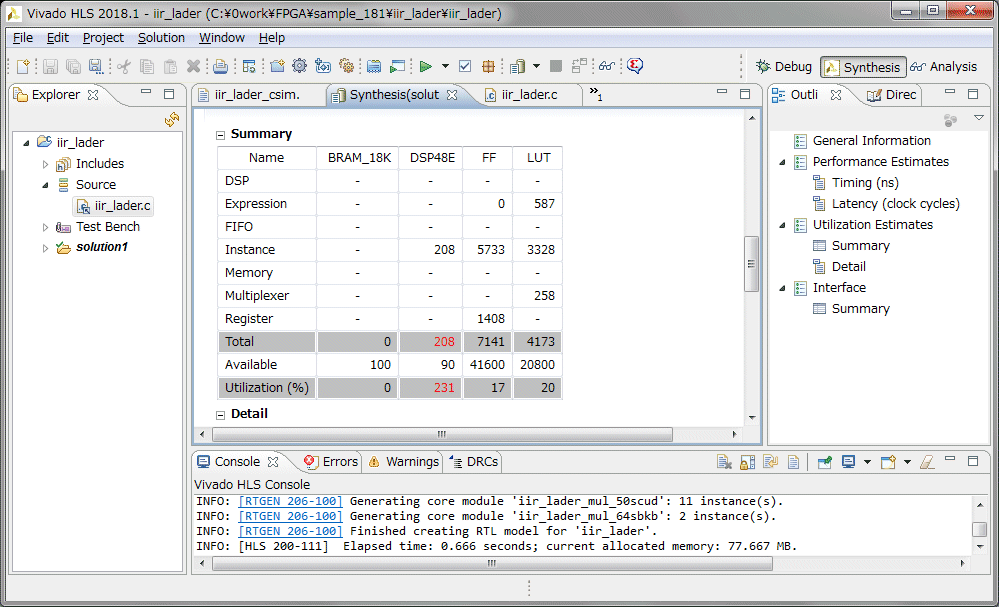
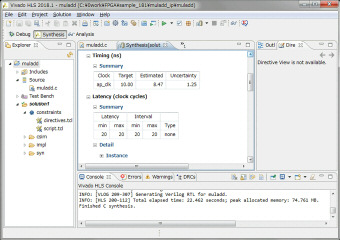
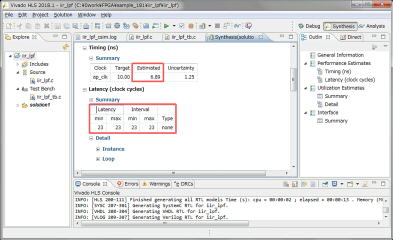
HLSのソースコードのlongを全てlong longに変更しました。ワーニングが無くなりました。続いてHLSで合成を行い、レンテンシとロジック使用量を確認します。動作速度は100MHz以上でも動作します。レイテンシは23クロック、データも23クロック毎に入力可能です。今回は音声帯域の48KHzのサンプリングなので、速度的には全く問題無さそうです。リソースですが、ARTYボードのXC7A35は乗算器(DSP48E)が90個しかないのですが、192個使っているというレポートが出ています。これはどのように対応すればいいのか~もう少し調査が必要です。
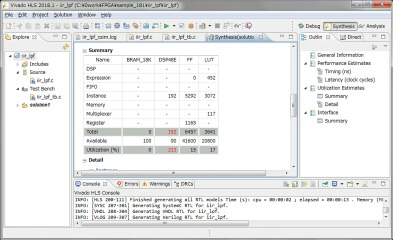
9月7日
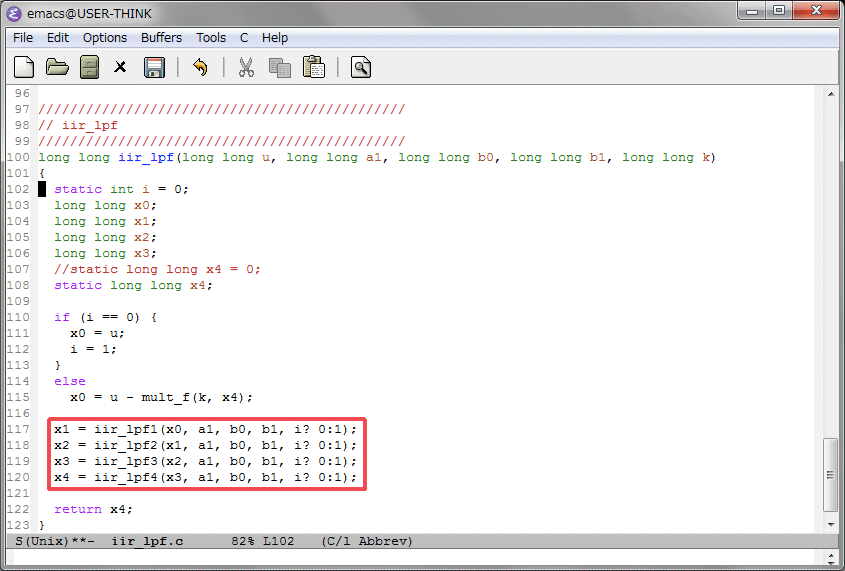
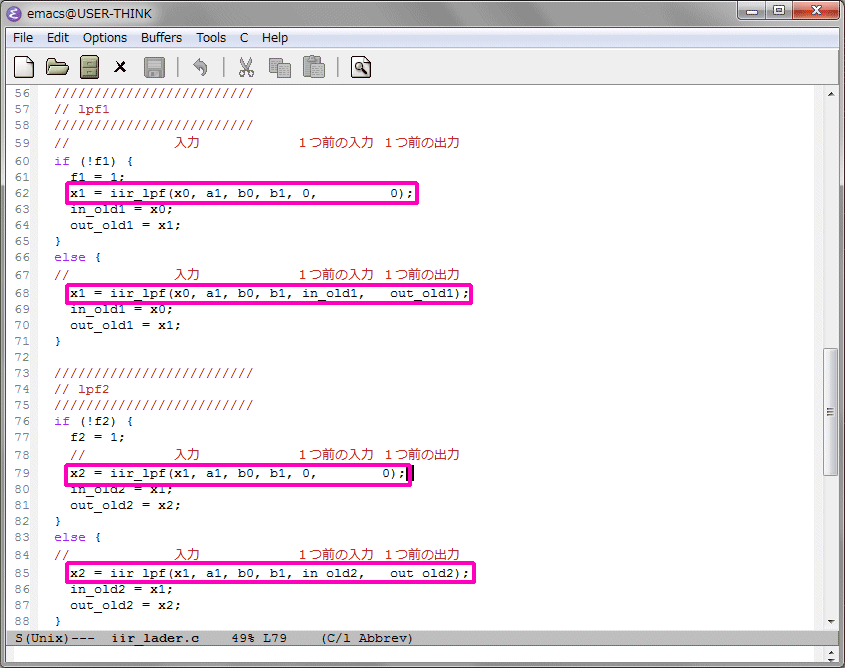
ラダーフィルタのコードは1次LPFの関数を別々に作り、4個直列に接続しています。各係数も同じで、同じ動作をしますが、処理後の出力結果を後で使う必要があるため、別関数になっています。これが原因で乗算器の使用量が多くなっているのではと思い、これを1つにしてみます。
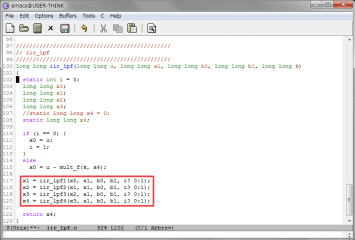
上位の関数でLPFの出力結果を個別に用意し、LPF本体を1つにします。コンパイル、シミュレーション続いてHLSで合成を行い、ロジック使用量を確認します。以前は192個だったものが208個に増えていました。これは失敗でした。
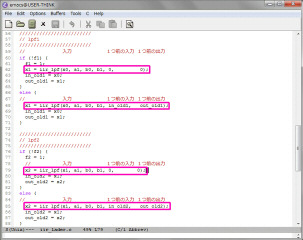
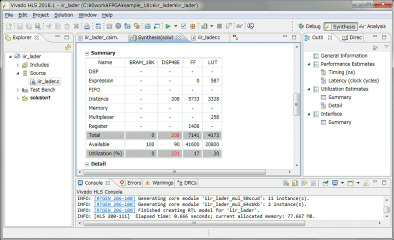
9月8日
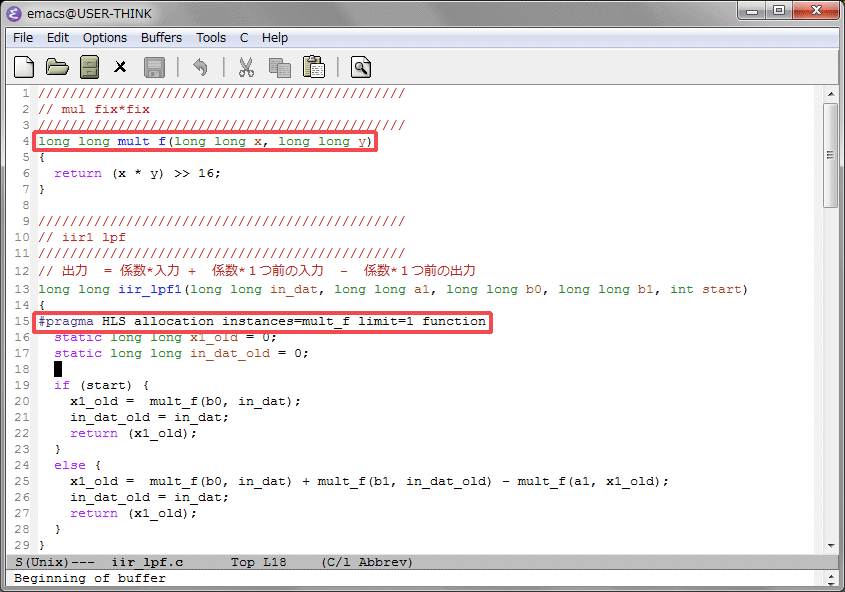
WEBページやユーザガイドなどを調べると、VivadoのHLSはデフォルトで速度重視で合成されることが判明しました。今回のラダーフィルタの動作クロックをSPI-DACと同じ15.36MHzにした場合でも、320クロック内に収まっていれば48KHzのSPI-DACのロードに間に合います。HLSの合成には色々な最適化指示が用意されています。指示は速度を早くするものが多いのですが、今回は動作速度を落として、リソースの使用量を減らす必要があります。このページが参考になります。使用する関数の数の制限するALLOCATIONという指示があり、mult_f関数を1つに制限してみます。これを4つのLPFのブロックの先頭に入れてみます。
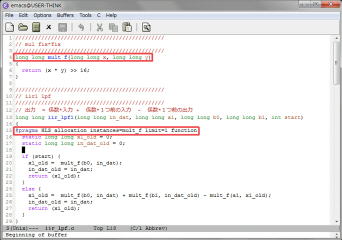
コンパイル、シミュレーション後に合成を行い、レンテンシとロジック使用量を確認します。動作速度は以前と同じ100MHz以上、レイテンシは73~80クロック、データも74~80クロック毎に入力可能です。レイテンシは3倍以上になりましたが、乗算器(DSP48E)の使用量は劇的に減って192個から16個になりました。10分の1以下になりましたが、仮に別のモジュールで乗算器を使わなくても、現状では8ch分は入らないことになります。
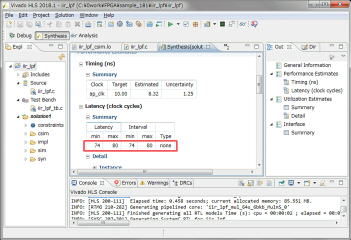
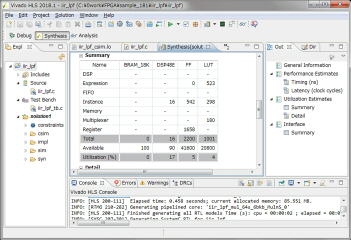
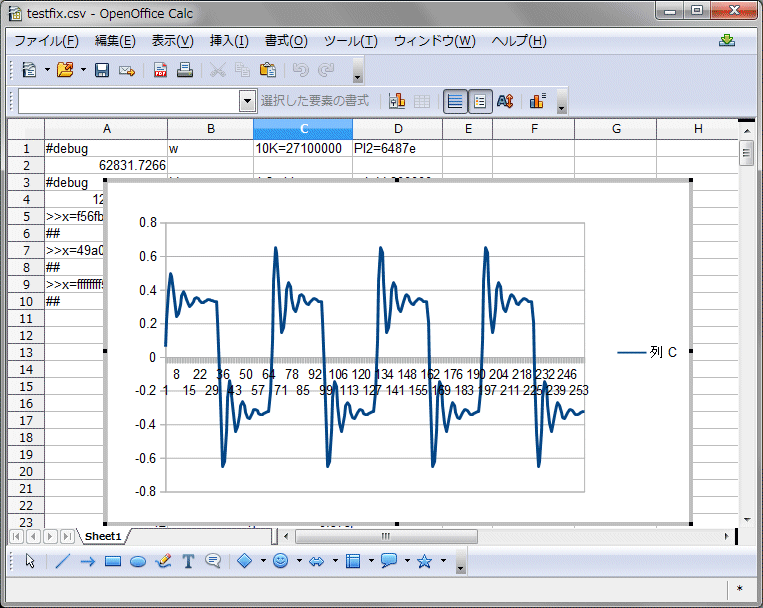
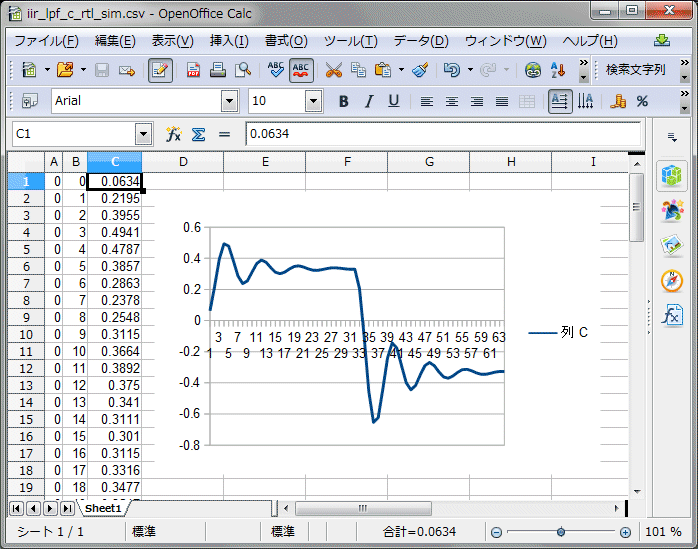
テストに使ったのは昨日と同じカットオフ10KHz、フィードバック2.0の1サイクル分です。シミュレーション時にコンソールに出力されたログから波形を作成しました。
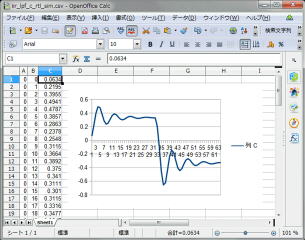
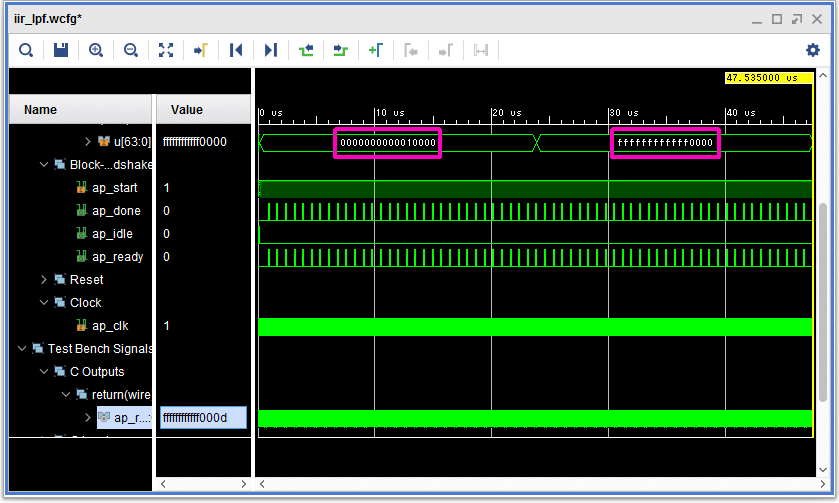
C/RTL協調シミュレーションを行うと、波形でタイミングを確認できます。テストベンチで設定している入力データの+1が32個、-1も32個分入力されています。
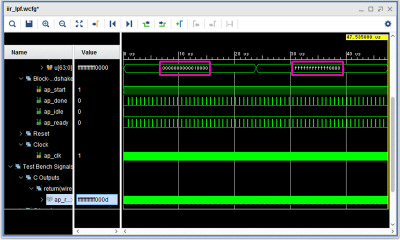
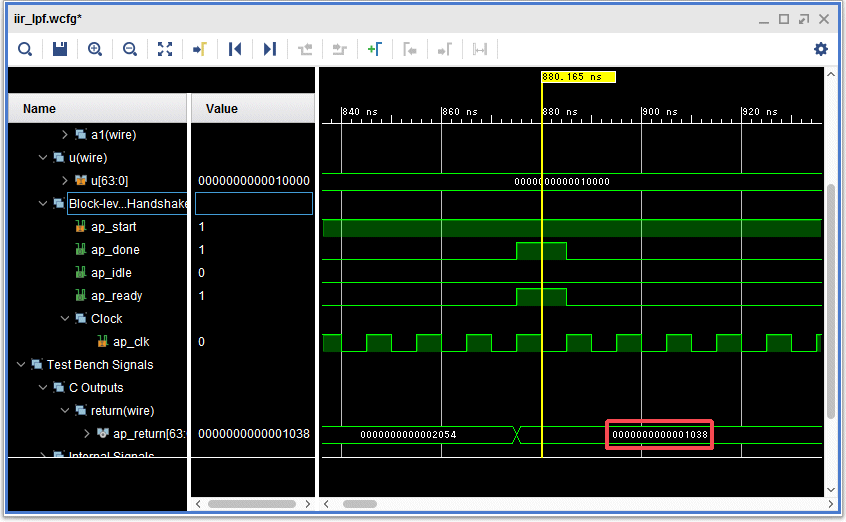
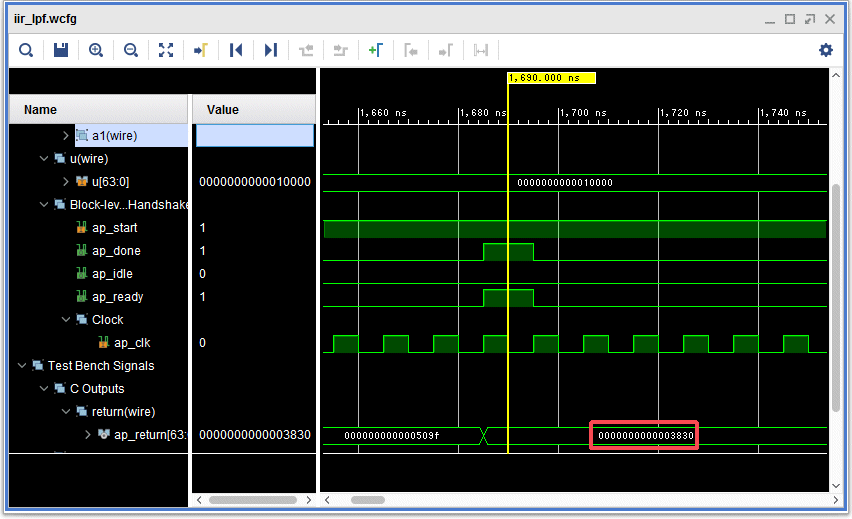
ラダーフィルタの出力結果の戻り値はap_ctrl_hsというハンドシェイク信号で確認できます。ap_doneは終了です。この信号の間隔は810nsecになっています。クロックは100MHzなので、80クロックに相当します。レポートのレイテンシと一致します。
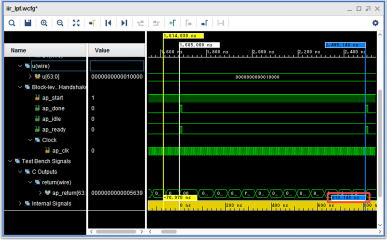
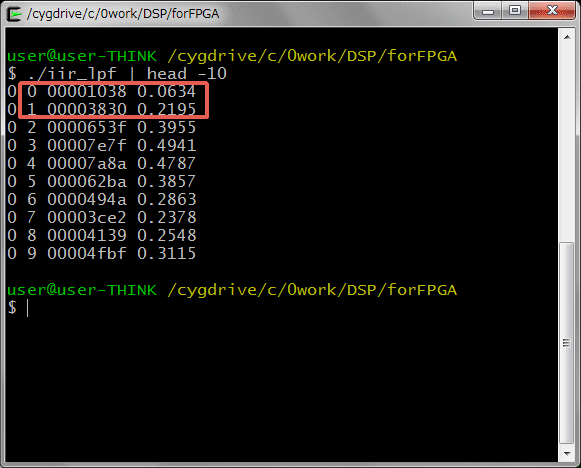
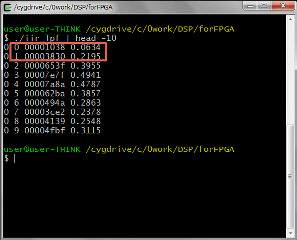
肝心の戻り値を確認してみます。先頭は1038で、2番目は3830です。上位の整数部は0なので、少数点以下の値と分かります。
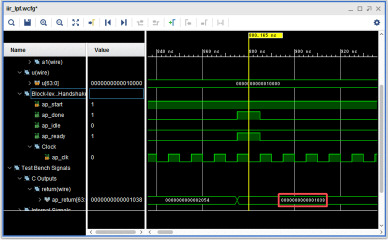
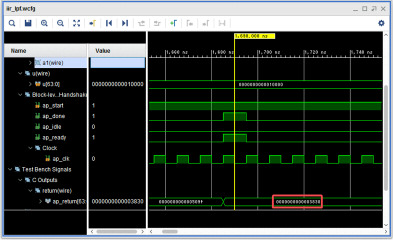
元のCの固定少数点版のプログラムに16進の出力を追加して比較します。1038と3830で合っています。CとCをHLSでRTLに変換したロジックの結果が同じになることを確認しました。まあ、そのように作られているので、当たり前なのですが、よく出来ています(笑)。現状では74~80クロックの最速で動作してしまうので、クロックを15.36MHzに設定し、SPI-DACのサンプリング周波数48KHz毎に計算させる必要があります。当面の目標はDDSの任意周波数の矩形波を入力し、SPI-DACに出力することです。
9月9日
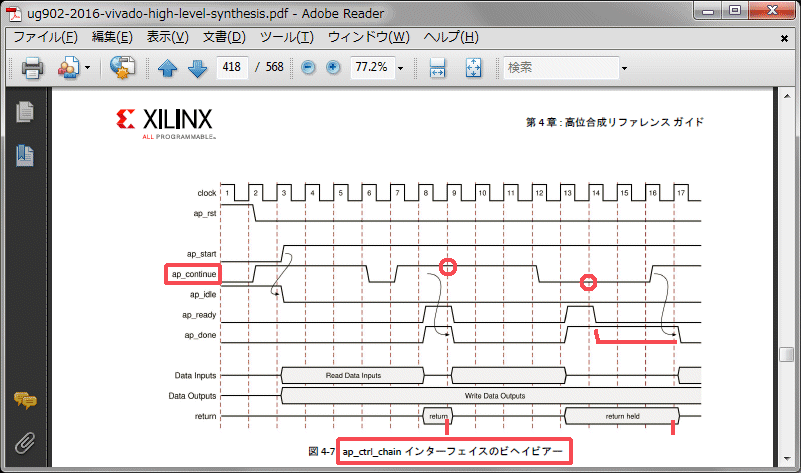
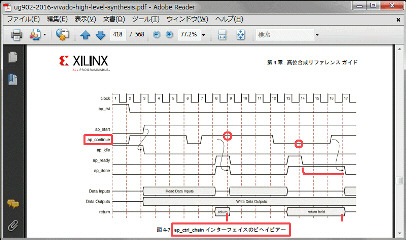
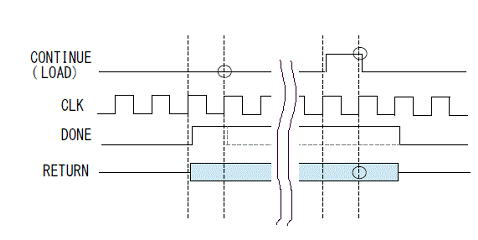
出力結果を外部信号に同期させて遅延させるap_ctrl_chainというインターフェースがあります。下はザイリンクスのHLSユーザガイドug902のタイミング図です。ap_ctrl_chainを選択するとap_continueという信号が増えて、ap_doneがhighの時に、この信号がhighでなければ終了が遅延されと書いてあります。
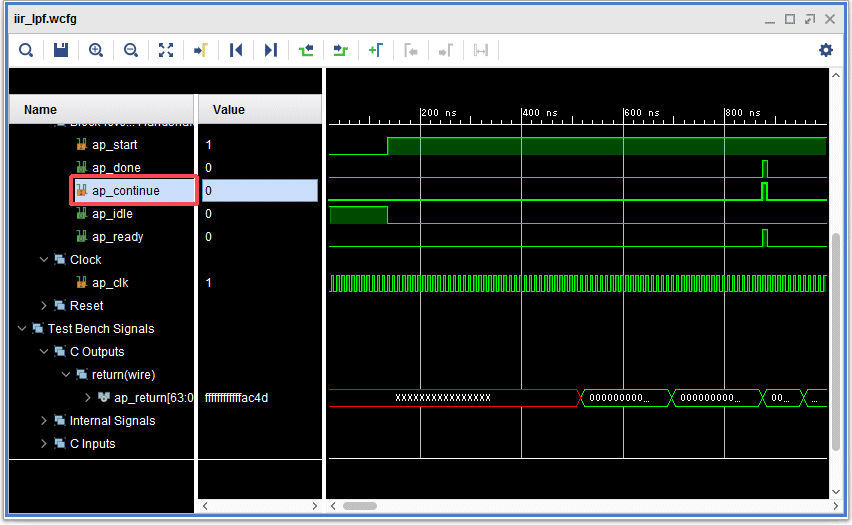
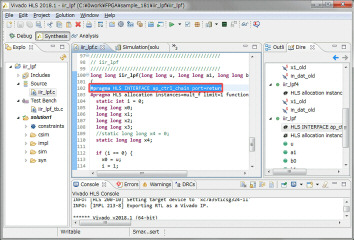
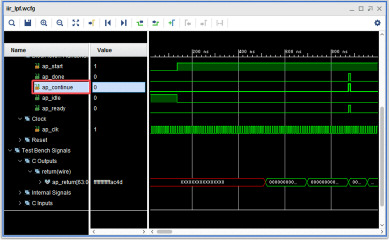
早速、最適化指示を追加してみます。C/RTL協調シミュレーションを行いタイミングを確認します。ap_continueはテストベンチで動作するようにap_doneと同じタイミングでhighになっています。実際にはラダーフィルタ部をIP化して外部からこのap_continue信号を制御すれば、48KHzサンプリングに合わせることができそうです。
9月10日
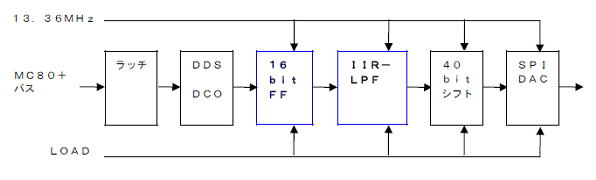
ap_continue信号はSPI-DACのLOAD信号で良さそうです。74~80クロックでap_done信号highになり、320クロックでap_continue信号がhighになるまでap_doneとラダーフィルタからの戻り値(RETURN)が引き伸ばされ、LOAD信号がhighの時に次段のモジュールにロードします。
実験するブロック図です。DDS-DCO(方形波出力)とSPI-DACは実装済みです。この間にデータ保持FFとラダーフィルタを実装します。